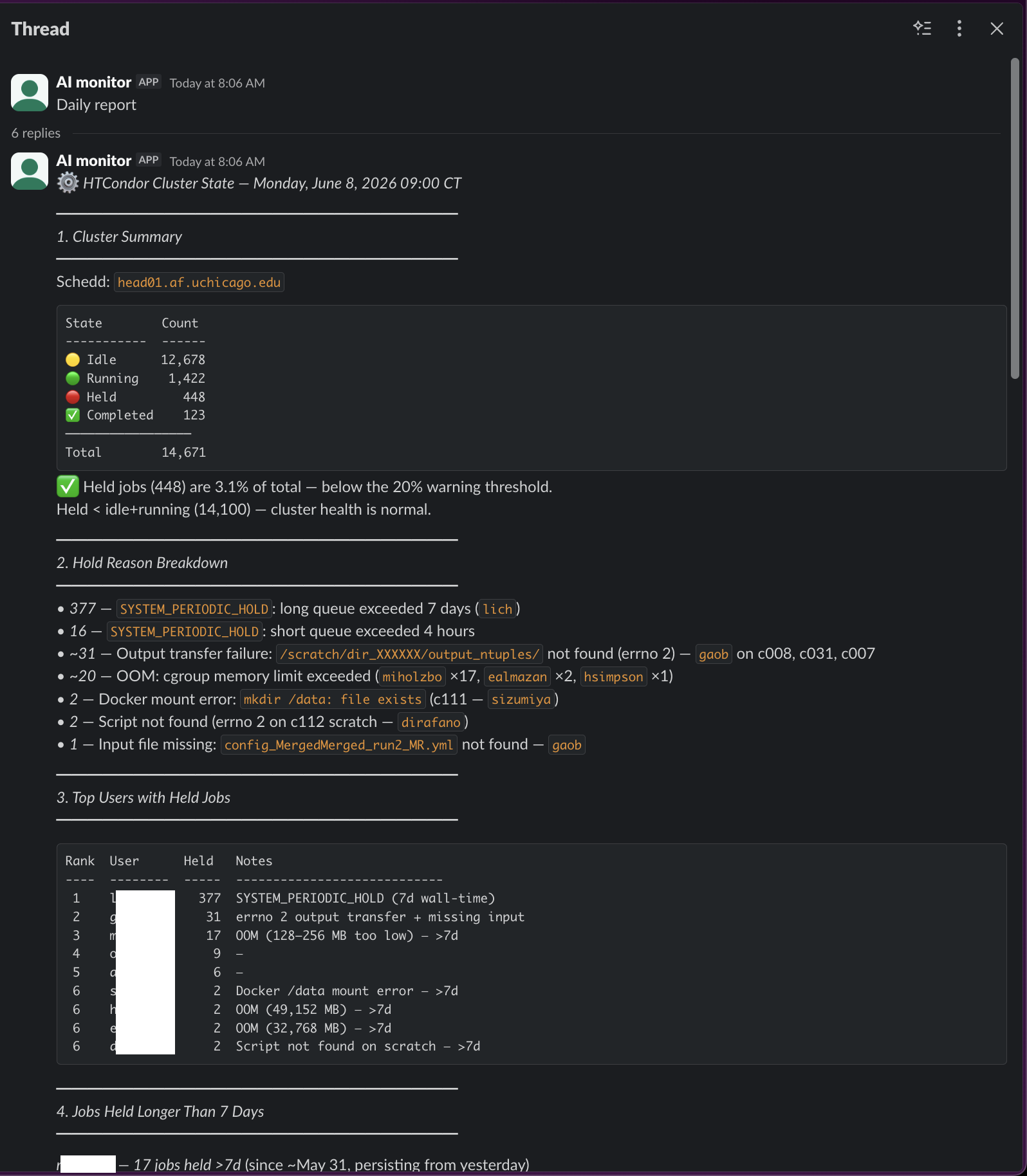
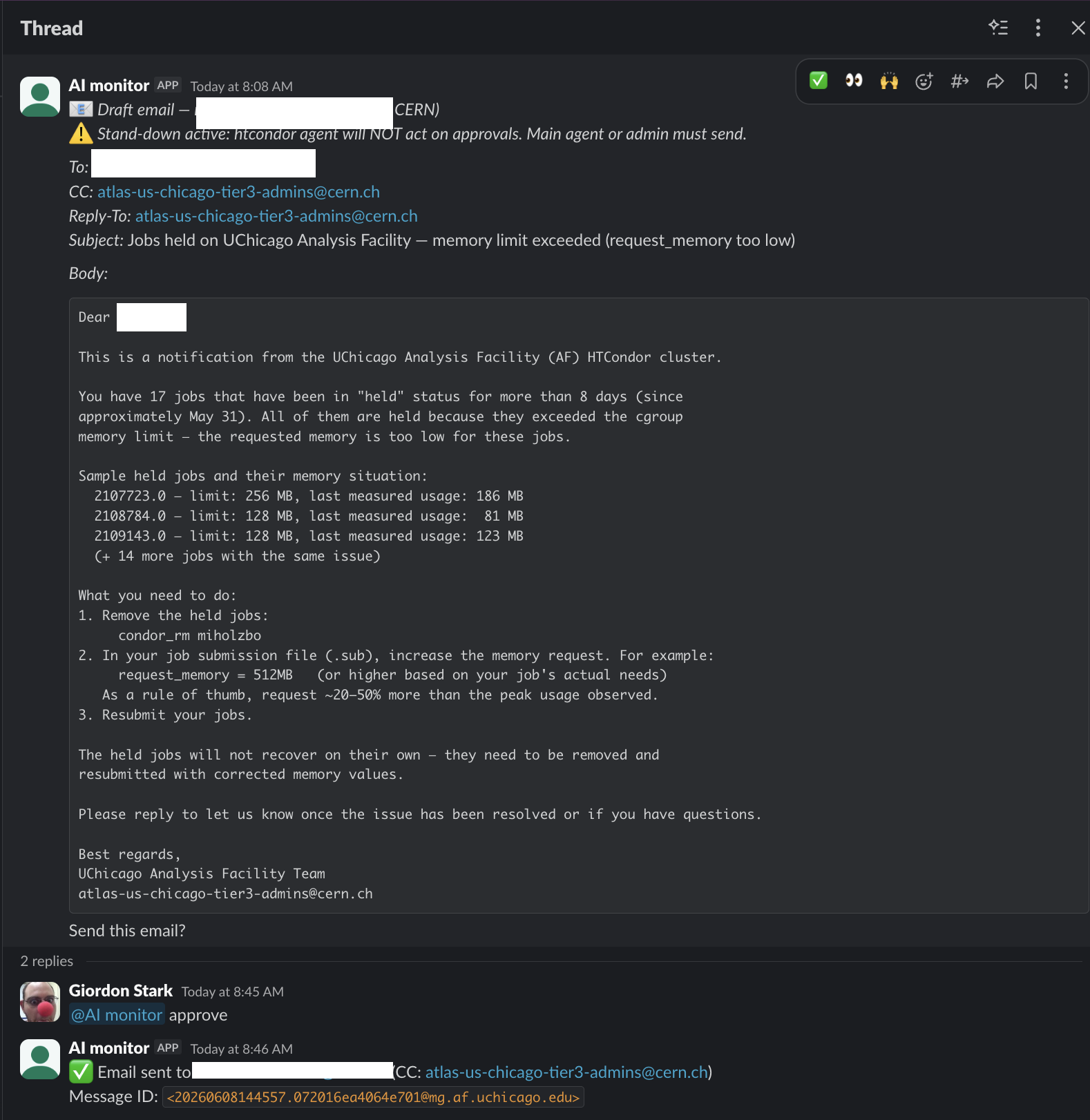
Your batch jobs emit big ntuples and small histograms. Where should each land on the AF?
A generic LLM
“Transfer the outputs back to submit node”, i.e. $HOME. The big ntuples blow the 100 GB /home quota almost immediately.
An LLM that knows the AF
big ntuples → /data (5 TB); small histograms → /home (100 GB). It knows the quotas and layout and mounts.
The thesis
The model didn’t get smarter. We gave it facility context. That gap, between a generic assistant and one that knows your storage, scheduler, and data, is the key.